This is a continuation of our Reference-Based Mastering article here.
Companies are facing unforeseen and unprecedented challenges due to COVID-19. To comply with social distancing, organizations have closed, and business, education and everyday social communications have switched to virtual settings.
As this new need emerged, a video communications organization received an overwhelming number of new registrants to utilize their videotelephony and online software. Facing rapid growth, they needed to scale their data integration process to qualify the influx of new registrants and the associated corporate data. Here’s how Matchbook AI SaaS helped them.
The Challenge
The large video communication company needed an integrated solution to qualify potential seats in companies of a certain size and type of work, through combining LinkedIn and DUNS company data. The sudden increase of 80,000 new registrations per day was creating a massive pool of unmatched and duplicated customer records.
Their current process for collecting customer information and matching the records to their internal database is highly manual and allows room for error. Web form data is often incomplete and unspecified, which leads to low match rates through the traditional batch matching process. The majority of their input data consists of only Name, Address, and Web Domain information, which can result in a high unmatched rate. This means a slow and laborintensive process of matching new records is required before exporting the new data into their internal systems.
D&B initially positioned their “Optimizer” solution to work in tandem with the customer’s CRM. This would automatically match and suggest supplemental matching calls to unique identifiers such as a web domain. However, this did not reduce the number of unmatched records upstream in the process mastering process.
The Solution
The Matchbook AI SaaS platform enables automation to achieve a highly accurate match rate at the initial step of the data integration process. From there, the client could continue to leverage “Optimizer” to manage the enrichment and monitoring within Salesforce. We undertook a proof of concept to identify the value we could create by addressing unstructured process and matching challenges. The POC consisted of working with a data set of 12,500 records to cleanse and match two candidate files with representative issues they were looking to overcome.
The matching workflow for the POC consisted of a two-pass processing of the data. The first pass served as an initial cleansing, including customized auto-matching and standardization focused on Name & Address data points. The second pass was an associated web domain address to match any remaining low confidence records. By using the web domain for each record, the client could ensure that they were matching to a unique identifier which removed the chance of duplicate records. In the first pass, we tried to find the web-domain owner within the specific country. When we did not find it there, we did a second pass match to find the company tied to that web-domain globally.
The Analysis
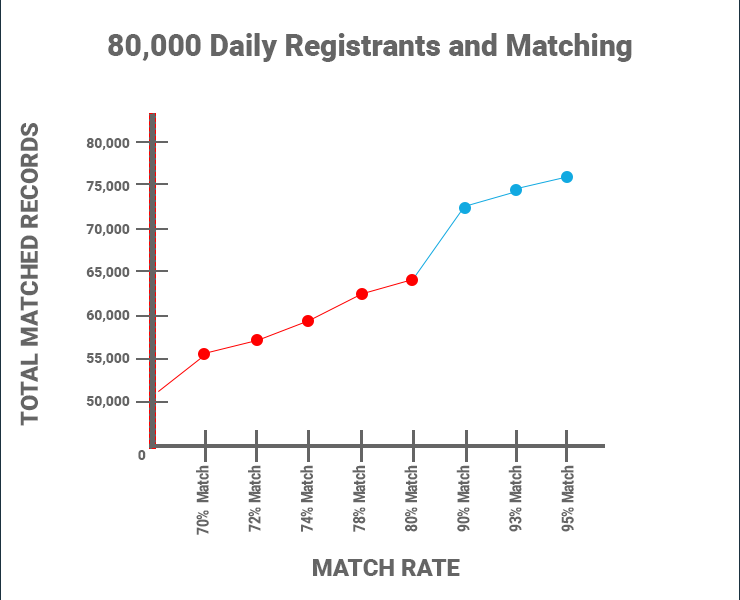
Through this iterative process, we improved automated matches from an initial 70-80% range up to over 95%. Manual stewardship capabilities can further increase match rates to near 100%. Resulting metrics illustrating these matching iterations are noted below:
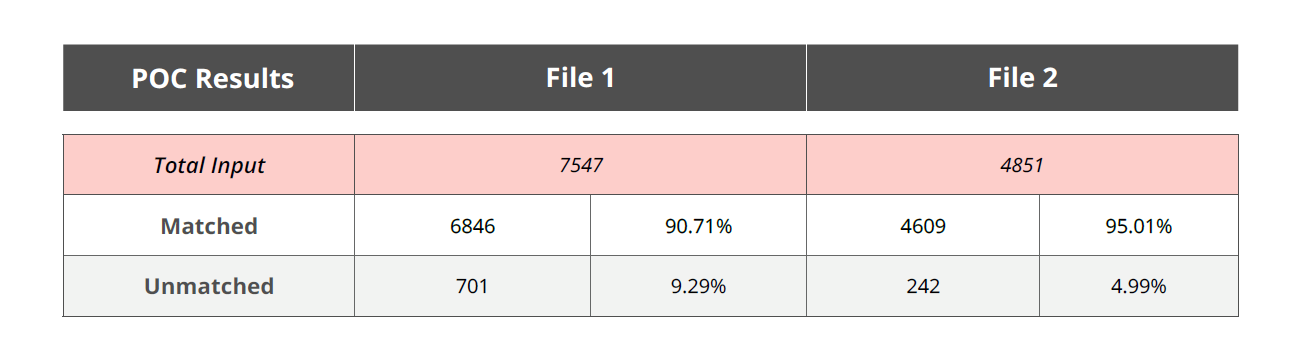
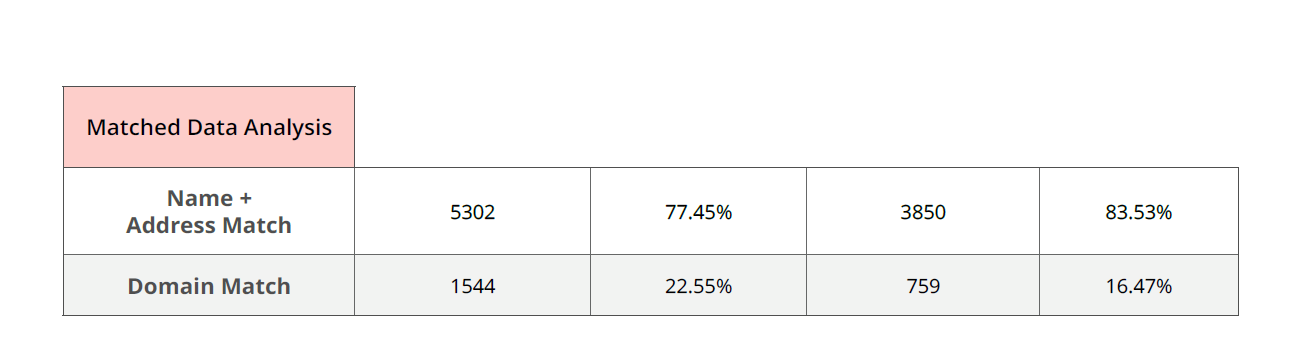
Resolution
By achieving a match rate of over 95%, the Video Communications organization will be able to successfully manage and match a 5-8x increase in incoming data without significantly scaling their teams. They are also able to run these processes in near real-time to get more accurately matched data within their Salesforce environment.